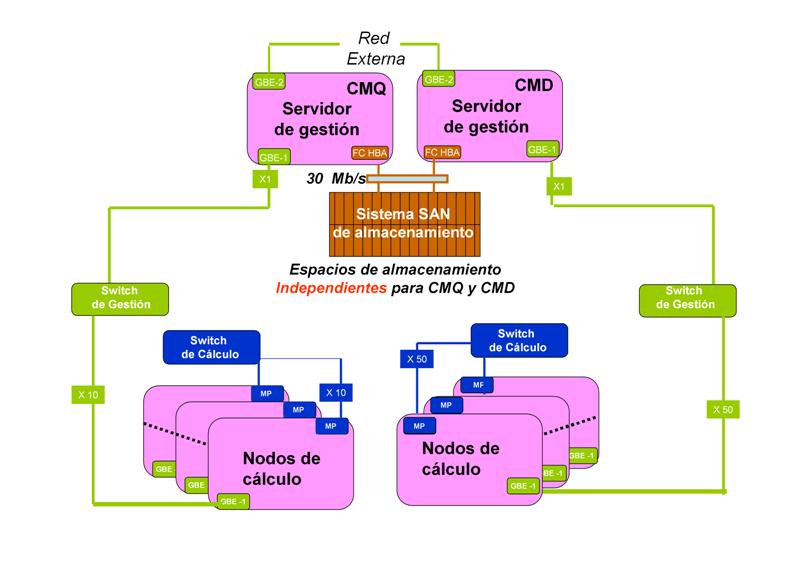
El cluster cmd está constituido por un conjunto de 50 nodos de cálculo de 2 vías (HP DL140, equipados con procesadores Xeon 3.6 GHz 2MB cache) controlados desde un servidor de gestión (HP DL380) que actúa como interface de todo el sistema y está conectado a una cabina de almacenamiento MSA1500. Para ver una imagen del esquema lógico de los clústeres cmq y cmd, pulse aquí.
| Nombre: | cmd.uniovi.es |
| IP: | 156.35.45.88 |
Más datos del acceso se encuentran aquí
Los nombres internos del nodo de gestión y los nodos de cálculo son:
| Nodo de control: | jaula02.sct.uo |
| Nodos de cálculo: | desde yed01.sct.uo a yed50.sct.uo |
El sistema operativo base del cluster Xeon es Linux de 64 bits para procesadores Intel EMT64. El comando uname –a. proporciona los detalles sobre la versión concreta instalada:
Linux jaula02 2.6.9-67.0.1.ELsmp #1 SMP Fri Nov 30 11:57:43 EST 2007 x86_64 x86_64 x86_64 GNU/Linux
Aquellos usuarios sin experiencia en sistemas Unix pueden encontrar más información aquí.
Los usuarios disponen de un directorio raíz en el sistema de ficheros /home localizado físicamente en el servidor de almacenamiento. Se dispone además de una segunda partición /data para albergar grandes ficheros de datos para aquellos usuarios que así lo demanden.
Ambas particiones, /home y /data, están controladas por el sistema de almacenamiento externo MSA1500 en configuración RAID5 que tolera el fallo de
un disco duro sin pérdida de información. Además de la configuración RAID5, el sistema de almacenamiento dispone de un disco duro en estado de reserva.
La conexión del /home o del /data al nodo de control transcurre por un cable de fibra de vidrio y una controladora SCSI. Esta cabina puede servir ficheros con una tasa de transferencia de 1-1.5 Gb/min.
Un comando df –h desde el nodo de control reporta:
Filesystem Size Used Avail Use% Mounted on /dev/cciss/c0d0p5 229G 16G 202G 8% /opt /dev/sda1 2.0T 823G 1.2T 41% /home /dev/sdb1 1.6T 25G 1.5T 2%
El sistema /home debe utilizarse para almacenar datos, códigos,
checkpoints o logs de ejecuciones, etc. Los trabajos que requieren el acceso a muchos datos (o los generen) deben diseñarse para que la escritura/lectura de los ficheros de datos o ficheros intermedios se haga exclusivamente en el disco local de los nodos de cálculo.
Los usuarios iniciales no están restringidos por cuotas de ocupación. Esta
situación puede cambiar en función de la evolución de la ocupación. Se realiza
un backup semanal del directorio /home.
El nodo de control jaula02 exporta el /home por NFS hacia los nodos de cálculo haciendo uso de la red Gigabit de administración.
Los nodos de cálculo disponen de dos discos duros SATA de 250 Gb de capacidad cada uno. Uno de los discos contiene una partición (sda4) destinada al directorio /scratch en el que se escribe y leen ficheros temporales de los trabajos. El segundo disco duro (sdb1) soporta el directorio /data cuya finalidad es albergar aquellos ficheros de datos que deban permanecer en el sistema con el propósito de ejecutar trabajos de análisis de datos.
Un comando df –h desde un nodo de cálculo reportaría:
/dev/sda4 187G 33M 178G 1% /scratch /dev/sdb1 230G 33M 218G 1% /data jaula02:/opt 229G 16G 202G 8% /opt jaula02:/home 2.0T 823G 1.2T 41% /home
Aquellos usuarios que realicen análisis masivos de datos serán incluidos en un grupo con acceso al directorio /data de los distintos nodos. El acceso a los datos distribuidos por el conjunto de servidores de cálculo se facilita por el servicio
automont, configurado en todos los nodos de cálculo, de modo que todos los discos
sdb1 constituyen un único sistema de archivos /pool. De esta manera, un nodo de cálculo, yed26
por ejemplo, puede acceder a los datos situados en otro nodo, yed40, sin más que apuntar al correspondiente directorio localizado en /pool como se indica en el ejemplo:
[usuario@yed26 ~]$ ls -l /pool/yed40 lrwxrwxrwx 1 root root 15 Jun 6 21:48 /pool/yed40 -> /mnt_pool/yed40
Así, pues, es posible preparar scripts de trabajos para el sistema colas que empleen datos distribuidos entre los distintos nodos.
El directorio /opt que cuelga del sistema de ficheros del nodo de gestión contiene las aplicaciones uso común. Este directorio está
exportado a todos los nodos de cálculo. Para ver las aplicaciones instaladas
(compiladores, librerías, programas de cálculo, etc.) pulse aquí.
Cada grupo de usuarios dispone de 5.0 GB de espacio reservado en el
directorio /opt/apps para instalar las
aplicaciones que sean de interés para el grupo. Así, dentro del directorio /opt/apps existe un subdirectorio para cada grupo con el nombre de grupo correspondiente, y con permisos de acceso sólo para los miembros del grupo.
El usuario puede siempre comprobar el estado de la cuota con la instrucción:
quota -g
A la hora de diseñar una configuración para el sistema de colas se ha tenido en cuenta el doble procesador disponible en cada nodo de cálculo y se ha supuesto que la situación más habitual será la de trabajos en espera. Asimismo, se ha tenido presente que la red de cálculo utiliza dos switches de comunicaciones. En la práctica, esto quiere decir que los trabajos paralelos que demanden varios nodos de cálculo es preferible ejecutarlos en nodos conectados a un mismo switch. La configuración del sistema de colas distribuye nodos entre los trabajos, más que procesadores entre trabajos, pues se consigue un mayor rendimiento y estabilidad del sistema de colas si los nodos de cálculo no comparten tareas de distintos trabajos.
Las características iniciales de las colas de cmd se resumen en la siguiente tabla:
Sistema de colas
| Nombre de la cola | cola8 | cola2 | cola2_express | dedcola100 |
| Número máximo de trabajos ejecutándose simultáneamente | 4 | 17 | 17 | 1 |
| Número máximo de CPUs disponible para un trabajo | 8 | 2 | 2 | 100 |
| Número máximo de nodos a utilizar por un trabajo | 4 | 1 | 2 | 50 |
| Tamaño máximo de fichero temporal en un trabajo (Gb) | 100 | 100 | 100 | |
| Límite de tiempo de reloj a consumir por un trabajo (horas) | 96:00:00 | 96:00:00 | 100 | |
| Número máximo de trabajos a ejecutar por un usuario | 1(1) | 5(3) | 5(3) | |
| Nodos asignados a la colas | 01 a 16 (par) | 17 a 33 (std) | 34 a 50 (exp) |
El uso del sistema de colas se encuentra descrito aquí.
Se recomienda seguir las siguientes pautas a la hora de enviar trabajos al sistema de colas:
cola2, cola2_express y cola8.Las características de las colas podrán modificarse en función de la evolución observada en la carga global del sistema y de las necesidades de los usuarios.
{kind=link}